




第一章:K8S介绍及部署
1、Kubernetes介绍
kubernetes(k8s)是2015年由Google公司基于Go语言编写的一款开源的容器集群编排系统,用于自动化容器的部署、扩缩容和管理;
kubernetes(k8s)是基于Google内部的Borg系统的特征开发的一个版本,集成了Borg系统大部分优势;
代码托管平台:https://github.com/Kubernetes
2、kubernetes具备的功能
自我修复:k8s可以监控容器的运行状况,并在发现容器出现异常时自动重启故障实例;
弹性伸缩:k8s可以根据资源的使用情况自动地调整容器的副本数。例如,在高峰时段,k8s可以自动增加容器的副本数以应对更多的流量;而在低峰时段,k8s可以减少应用的副本数,节省资源;
资源限额:k8s允许指定每个容器所需的CPU和内存资源,能够更好的管理容器的资源使用量;
滚动升级:k8s可以在不中断服务的情况下滚动升级应用版本,确保在整个过程中仍有足够的实例在提供服务;
负载均衡:k8s可以根据应用的负载情况自动分配流量,确保各个实例之间的负载均衡,避免某些实例过载导致的性能下降;
服务发现:k8s可以自动发现应用的实例,并为它们分配一个统一的访问地址。这样,用户只需要知道这个统一的地址,就可以访问到应用的任意实例,而无需关心具体的实例信息;
存储管理:k8s可以自动管理应用的存储资源,为应用提供持久化的数据存储。这样,在应用实例发生变化时,用户数据仍能保持一致,确保数据的持久性;
密钥与配置管理:Kubernetes 允许你存储和管理敏感信息,例如:密码、令牌、证书、ssh密钥等信息进行统一管理,并共享给多个容器复用;
3、kubernetes集群角色
k8s集群需要建⽴在多个节点上,将多个节点组建成一个集群,然后进⾏统⼀管理,但是在k8s集群内部,这些节点⼜被划分成了两类⻆⾊:
一类⻆⾊为主节点,叫Master,负责集群的所有管理工作,和协调集群中运行的容器应用;
⼀类⻆⾊为⼯作节点,叫Node,负责运行集群中所有用户的容器应用, 执行实际的工作负载 ;
Master管理节点组件:
API Server:作为集群的控制中心,处理外部和内部通信,接收用户请求并处理集群内部组件之间的通信;
Scheduler:负责将待部署的 Pods 分配到合适的 Node 节点上,根据资源需求、策略和约束等因素进行调度;
Controller Manager:管理集群中的各种控制器,例如 Deployment、ReplicaSet、Node 控制器等,管理集群中的各种资源;
etcd:作为集群的数据存储,保存集群的配置信息和状态信息;
Node工作节点组件:
Kubelet:负责与 Master 节点通信,并根据 Master 节点的调度决策来创建、更新和删除 Pod,同时维护 Node 节点上的容器状态;
容器运行时(如 Docker、containerd 等):负责运行和管理容器,提供容器生命周期管理功能。例如:创建、更新、删除容器等;
Kube-proxy:负责为集群内的服务实现网络代理和负载均衡,确保服务的访问性;
非必须的集群插件:
DNS服务:严格意义上的必须插件,在k8s中,很多功能都需要用到DNS服务,例如:服务发现、负载均衡、有状态应用的访问等;
Dashboard: 是k8s集群的Web管理界面;
资源监控:例如metrics-server监视器,用于监控集群中资源利用率;
4、kubernetes集群类型
一主多从集群:由一台Master管理节点和多台Node工作节点组成,生产环境下Master节点存在单点故障的风险,适合学习和测试环境使用;
多主多从集群:由多台Master管理节点和多Node工作节点组成,安全性高,适合生产环境使用;
5、kubernetes集群规划
6、集群前期环境准备
修改每个节点主机名
hostnamectl set-hostname master01
hostnamectl set-hostname master02
hostnamectl set-hostname master03
hostnamectl set-hostname worker01
hostnamectl set-hostname k8s-ha1
hostnamectl set-hostname k8s-ha2以下前期环境准备需要在所有节点都执行
配置集群之间本地解析,集群在初始化时需要能够解析主机名
echo "192.168.0.10 master01" >> /etc/hosts
echo "192.168.0.11 master02" >> /etc/hosts
echo "192.168.0.12 master03" >> /etc/hosts
echo "192.168.0.13 worker01" >> /etc/hosts
echo "192.168.0.14 worker02" >> /etc/hosts
echo "192.168.0.70 k8s-ha1" >> /etc/hosts
echo "192.168.0.71 k8s-ha2" >> /etc/hosts开启bridge网桥过滤功能
bridge(桥接) 是 Linux 系统中的一种虚拟网络设备,它充当一个虚拟的交换机,为集群内的容器提供网络通信功能,容器就可以通过这个 bridge 与其他容器或外部网络通信了。
cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
#参数解释
net.bridge.bridge-nf-call-ip6tables = 1 //对网桥上的IPv6数据包通过iptables处理
net.bridge.bridge-nf-call-iptables = 1 //对网桥上的IPv4数据包通过iptables处理
net.ipv4.ip_forward = 1 //开启IPv4路由转发,来实现集群中的容器与外部网络的通信#由于开启bridge功能,需要加载br_netfilter模块来允许在bridge设备上的数据包经过iptables防火墙处理
modprobe br_netfilter && lsmod | grep br_netfilter
#...会输出以下内容
br_netfilter 22256 0
bridge 151336 1 br_netfilter
#参数解释:
modprobe //命令可以加载内核模块
br_netfilter //模块模块允许在bridge设备上的数据包经过iptables防火墙处理#加载配置文件,使上述配置生效
sysctl -p /etc/sysctl.d/k8s.conf配置ipvs功能
在k8s中Service有两种代理模式,一种是基于iptables的,一种是基于ipvs,两者对比ipvs负载均衡算法更加的灵活,且带有健康检查的功能,如果想要使用ipvs模式,需要手动载入ipvs模块。
ipset 和 ipvsadm 是两个与网络管理和负载均衡相关的软件包,在k8s代理模式中,提供多种负载均衡算法,如轮询(Round Robin)、最小连接(Least Connection)和加权最小连接(Weighted Least Connection)等;
yum -y install ipset ipvsadm将需要加载的ipvs相关模块写入到文件中
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
#模块介绍
ip_vs //提供负载均衡的模块,支持多种负载均衡算法,如轮询、最小连接、加权最小连接等
ip_vs_rr //轮询算法的模块(默认算法)
ip_vs_wrr //加权轮询算法的模块,根据后端服务器的权重值转发请求
ip_vs_sh //哈希算法的模块,同一客户端的请求始终被分发到相同的后端服务器,保证会话一致性
nf_conntrack //链接跟踪的模块,用于跟踪一个连接的状态,例如 TCP 握手、数据传输和连接关闭等执行文件来加载模块
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack关闭SWAP分区
为了保证 kubelet 正常工作,k8s强制要求禁用,否则集群初始化失败
#临时关闭
swapoff -a
#永久关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab
grep ".*swap.*" /etc/fstab检查swap
free -h
...
Swap: 0B 0B 0B7、Docker环境准备
所有集群主机安装,不包括负载均衡节点
#安装yum-utils创建docker存储库(阿里)
yum install -y yum-utils && yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo#安装指定版本并设置启动及开机自启动
yum -y install docker-ce-20.10.9-3.el78、配置Cgroup驱动程序
启用Cgroup控制组,用于限制进程的资源使用量,如CPU、内存、磁盘IO等
#在/etc/docker/daemon.json添加如下内容
mkdir /etc/docker
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF#启动服务并设置随机自启
systemctl enable docker ; systemctl start docker9、HAProxy及keepalived部署
此处的haproxy为apiserver提供反向代理,集群的管理请求通过VIP进行接收,haproxy将所有管理请求轮询转发到每个master节点上。
Keepalived为haproxy提供vip(192.168.0.100)在二个haproxy实例之间提供主备,降低当其中一个haproxy失效时对服务的影响。
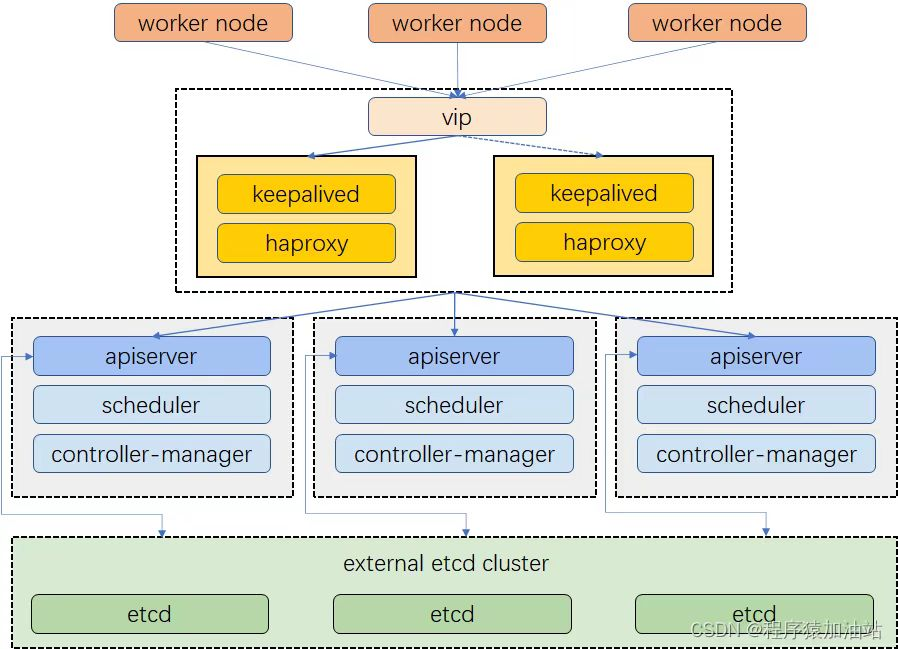
提示:以下操作只需要在k8s-ha1、k8s-ha2配置。
yum -y install haproxy keepalivedhaproxy配置文件内容如下
该配置文件内容在k8s-ha1与k8s-ha2节点保持一致
cat /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
# Example configuration for a possible web application. See the
# full configuration options online.
#
#
#---------------------------------------------------------------------
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
maxconn 2000 #单个进程最大并发连接数
ulimit-n 16384 #每个进程可以打开的文件数量
log 127.0.0.1 local0 err #日志输出配置,所有日志都记录在本机系统日志,通过 local0 输出
stats timeout 30s #连接socket超时时间
defaults
log global #定义日志为global(全局)
mode http #使用的连接协议
option httplog #日志记录选项,httplog表示记录与HTTP会话相关的日志
timeout connect 5000 #定义haproxy将客户端请求转发至后端服务器所等待的超时时长
timeout client 50000 #客户端非活动状态的超时时长
timeout server 50000 #客户端与服务器端建立连接后,等待服务器端的超时时长
timeout http-request 15s #客户端建立连接但不请求数据时,关闭客户端连接超时时间
timeout http-keep-alive 15s # session 会话保持超时时间
frontend monitor-in #监控haproxy服务本身
bind *:33305 #监听的端口
mode http #使用的连接协议
option httplog #日志记录选项,httplog表示记录与HTTP会话相关的日志
monitor-uri /monitor #监控URL路径
frontend k8s-master #接收请求的前端名称,名称自定义,类似于Nginx的一个虚拟主机server。
bind 0.0.0.0:6443 #监听客户端请求的 IP地址和端口(以包含虚拟IP)
bind 127.0.0.1:6443
mode tcp #使用的连接协议
option tcplog #日志记录选项,tcplog表示记录与tcp会话相关的日志
tcp-request inspect-delay 5s #等待数据传输的最大超时时间
default_backend k8s-master #将监听到的客户端请求转发到指定的后端
backend k8s-master #后端服务器组,要与前端中设置的后端名称一致
mode tcp #使用的连接协议
option tcplog #日志记录选项,tcplog表示记录与tcp会话相关的日志
option tcp-check #tcp健康检查
balance roundrobin #负载均衡方式为轮询
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server master01 192.168.0.10:6443 check # 根据自己环境修改后端实例IP
server master02 192.168.0.11:6443 check # 根据自己环境修改后端实例IP
server master03 192.168.0.12:6443 check # 根据自己环境修改后端实例IPk8s-ha1与k8s-ha2启动haproxy
systemctl start haproxy
systemctl enable haproxy
systemctl status haproxyk8s-ha1节点keepalived配置文件内容如下
cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state MASTER
interface ens32
virtual_router_id 51
priority 101
advert_int 2
authentication {
auth_type PASS
auth_pass abc123
}
virtual_ipaddress {
192.168.0.100/24
}
track_script {
chk_apiserver
}
}配置文件详解
#定义一个自定义脚本,名称为chk_apiserver
vrrp_script chk_apiserver {
#脚本所在的路径及名称
script "/etc/keepalived/check_apiserver.sh"
#监控检查的时间间隔,单位秒
interval 5
#健康检车的次数,连续2次健康检查失败,服务器将被标记为不健康
fall 2
#连续健康检查成功的次数,有1次健康检查成功,服务器将被标记为健康
rise 1
}
#配置了一个名为VI_1的VRRP实例组
vrrp_instance VI_1 {
#该节点在VRRP组中的身份,Master节点负责处理请求并拥有虚拟IP地址
state MASTER
#实例绑定的网络接口,实例通过这个网络接口与其他VRRP节点通信,以及虚拟IP地址的绑定
interface ens32
#虚拟的路由ID,范围1到255之间的整数,用于在一个网络中区分不同的VRRP实例组,但是在同一个VRRP组中的节点,该ID要保持一致
virtual_router_id 51
#实例的优先级,范围1到254之间的整数,用于决定在同一个VRRP组中哪个节点将成为Master节点,数字越大优先级越>高
priority 101
#Master节点广播VRRP报文的时间间隔,用于通知其他Backup节点Master节点的存在和状态,在同一个VRRP组中,所有>节点的advert_int参数值必须相同
advert_int 2
#实例之间通信的身份验证机制
authentication {
#PASS为密码验证
auth_type PASS
#此密码必须为1到8个字符,在同一个VRRP组中,所有节点必须使用相同的密码,以确保正确的身份验证和通信
auth_pass abc123
}
#定义虚拟IP地址
virtual_ipaddress {
192.168.0.100/24
}
#引用自定义脚本,名称与上方vrrp_script中定义的名称保持一致
track_script {
chk_apiserver
}
}k8s-ha1定义检测haproxy脚本
cat /etc/keepalived/check_apiserver.sh
#!/bin/bash
err=0
for k in $(seq 1 3)
do
check_code=$(pgrep haproxy)
if [[ $check_code == "" ]]; then
err=$(expr $err + 1)
sleep 1
continue
else
err=0
break
fi
done
if [[ $err != "0" ]]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
fi脚本添加执行权限
chmod +x /etc/keepalived/check_apiserver.shk8s-ha2节点keepalived配置文件内容如下
cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state BACKUP #需要修改节点身份
interface ens32
virtual_router_id 51
priority 99 #备用节点优先级不能高于master
advert_int 2
authentication {
auth_type PASS
auth_pass abc123
}
virtual_ipaddress {
192.168.0.100/24
}
track_script {
chk_apiserver
}
}k8s-ha2定义检测haproxy脚本
cat /etc/keepalived/check_apiserver.sh
#!/bin/bash
err=0
for k in $(seq 1 3)
do
check_code=$(pgrep haproxy)
if [[ $check_code == "" ]]; then
err=$(expr $err + 1)
sleep 1
continue
else
err=0
break
fi
done
if [[ $err != "0" ]]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi脚本添加执行权限
chmod +x /etc/keepalived/check_apiserver.shk8s-ha1与k8s-ha2节点启动keepalived
systemctl start keepalived
systemctl enable keepalived
systemctl status keepalived查看集群VIP地址
查看VIP(提示:ifconfig命令查看不到VIP)
[root@k8s-ha1 ~]# ip a s ens3210、k8s集群部署方式
kubernetes集群有多种部署方式,目前常用的部署方式有如下两种:
kubeadm部署方式:kubeadm是一个快速搭建kubernetes的集群工具
二进制包部署方式:从官网下载每个组件的二进制包,依次去安装,部署麻烦
其他方式:通过一些开源的工具搭建,例如:sealos
11、k8s YUM源准备
本实验使用阿里云YUM源
集群所有节点都安装,不包括负载均衡节点
cat > /etc/yum.repos.d/k8s.repo <<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF12、集群软件安装
安装集群软件,本实验安装k8s 1.23.0版本软件
kubeadm:用于初始化集群,并配置集群所需的组件并生成对应的安全证书和令牌;
kubelet:负责与 Master 节点通信,并根据 Master 节点的调度决策来创建、更新和删除 Pod,同时维护 Node 节点上的容器状态;
kubectl:用于管理k8集群的一个命令行工具;
集群所有节点都安装,不包括负载均衡节点
#安装指定版本
yum install -y kubeadm-1.23.0-0 kubelet-1.23.0-0 kubectl-1.23.0-013、配置kubelet
启用Cgroup控制组,用于限制进程的资源使用量,如CPU、内存、磁盘IO等
cat > /etc/sysconfig/kubelet <<EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
EOF#设置kubelet为开机自启动即可,集群初始化后自动启动
systemctl enable kubelet14、集群初始化
查看集群所需镜像文件
[root@master01 ~]# kubeadm config images list
#...以下是集群初始化所需的集群组件镜像
v1.27.1; falling back to: stable-1.23
k8s.gcr.io/kube-apiserver:v1.23.17
k8s.gcr.io/kube-controller-manager:v1.23.17
k8s.gcr.io/kube-scheduler:v1.23.17
k8s.gcr.io/kube-proxy:v1.23.17
k8s.gcr.io/pause:3.6
k8s.gcr.io/etcd:3.5.1-0
k8s.gcr.io/coredns/coredns:v1.8.6在master01节点初始化集群,需要创建集群初始化配置文件
[root@master01 ~]# kubeadm config print init-defaults > kubeadm-config.yaml配置文件需要修改如下内容
[root@master01 ~]# vim kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: 7t2weq.bjbawausm0jaxury
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.0.10 #根据自己环境修改IP
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: master01
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
certSANs:
- 192.168.0.100 #在证书中指定的可信IP地址,负载均衡的VIP
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 192.168.0.100:6443 #负载均衡器的IP,主要让Kubernetes知道生成主节点令牌
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers #集群组件镜像仓库地址
kind: ClusterConfiguration
kubernetesVersion: v1.23.0 #集群版本
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16 #pod网络
serviceSubnet: 10.96.0.0/12 #service网络
scheduler: {}#初始化集群
[root@master01 ~]# kubeadm init --config /root/kubeadm-config.yaml --upload-certs
#选项说明:
--upload-certs //初始化过程将生成证书,并将其上传到etcd存储中,否则节点无法加入集群提示:如果哪个节点出现问题,可以使用下列命令重置当前节点
kubeadm reset初始化成功后,按照提示执行下边命令
[root@master01 ~]# export KUBECONFIG=/etc/kubernetes/admin.conf
[root@master01 ~]# mkdir -p $HOME/.kube
[root@master01 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master01 ~]# chown $(id -u):$(id -g) $HOME/.kube/config15、Master节点加入集群
提示:按照自己当前集群生成的token在master02、master03节点执行
16、工作节点加入集群
提示:按照自己当前集群生成的token在worker01、worker02节点执行
17、部署Calico网络
Calico 和 Flannel 是两种流行的 k8s 网络插件,它们都为集群中的 Pod 提供网络功能。然而,它们在实现方式和功能上有一些重要区别:
网络模型的区别:
Calico 使用 BGP(边界网关协议)作为其底层网络模型。它利用 BGP 为每个 Pod 分配一个唯一的 IP 地址,并在集群内部进行路由。Calico 支持网络策略,可以对流量进行精细控制,允许或拒绝特定的通信。
Flannel 则采用了一个简化的覆盖网络模型。它为每个节点分配一个 IP 地址子网,然后在这些子网之间建立覆盖网络。Flannel 将 Pod 的数据包封装到一个更大的网络数据包中,并在节点之间进行转发。Flannel 更注重简单和易用性,不提供与 Calico 类似的网络策略功能。
性能的区别:
由于 Calico 使用 BGP 进行路由,其性能通常优于 Flannel。Calico 可以实现直接的 Pod 到 Pod 通信,而无需在节点之间进行额外的封装和解封装操作。这使得 Calico 在大型或高度动态的集群中具有更好的性能。
Flannel 的覆盖网络模型会导致额外的封装和解封装开销,从而影响网络性能。对于较小的集群或对性能要求不高的场景,这可能并不是一个严重的问题。
在k8s-master01节点安装Calico网络即可
#下载calico文件
wget https://raw.githubusercontent.com/projectcalico/calico/v3.24.1/manifests/calico.yaml
#创建calico网络
kubectl apply -f calico.yaml
#查看calico的Pod状态是否为Running
kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-66966888c4-whdkj 1/1 Running 0 101s
calico-node-f4ghp 1/1 Running 0 101s
calico-node-sj88q 1/1 Running 0 101s
calico-node-vnj7f 1/1 Running 0 101s
calico-node-vwnw4 1/1 Running 0 101s18、验证集群可用性
#查看所有的节点
[root@master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane,master 25m v1.23.0
master02 Ready control-plane,master 25m v1.23.0
master03 Ready control-plane,master 24m v1.23.0查看kubernetes集群pod运行情况
[root@master01 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-558bd4d5db-smp62 1/1 Running 0 13m
coredns-558bd4d5db-zcmp5 1/1 Running 0 13m
etcd-master01 1/1 Running 0 14m
etcd-master02 1/1 Running 0 3m10s
etcd-master03 1/1 Running 0 115s
kube-apiserver-master01 1/1 Running 0 14m
kube-apiserver-master02 1/1 Running 0 3m13s
kube-apiserver-master03 1/1 Running 0 116s
kube-controller-manager-master01 1/1 Running 1 13m
kube-controller-manager-master02 1/1 Running 0 3m13s
kube-controller-manager-master03 1/1 Running 0 116s
kube-proxy-629zl 1/1 Running 0 2m17s
kube-proxy-85qn8 1/1 Running 0 3m15s
kube-proxy-fhqzt 1/1 Running 0 13m
kube-proxy-jdxbd 1/1 Running 0 3m40s
kube-proxy-ks97x 1/1 Running 0 4m3s
kube-scheduler-master01 1/1 Running 1 13m
kube-scheduler-master02 1/1 Running 0 3m13s
kube-scheduler-master03 1/1 Running 0 115s
19、部署Nginx程序测试
#部署nginx程序(提前将镜像导入到worker01、worker02节点)
[root@master ~]# kubectl create deployment nginx --image=choujiang_ngx:v1
#开放端口
[root@master ~]# kubectl expose deployment nginx --port=80 --type=NodePort
#查看pod状态
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-696649f6f9-j8zbj 1/1 Running 0 2m1s
#查看service状态
[root@master ~]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 44m
nginx NodePort 10.103.195.31 <none> 80:32554/TCP 96s
#浏览器访问测试
http://192.168.0.30:32554/20、kuboard k8s多集群管理平台
在K8S集群之外准备一台主机安装docker,并通过docker安装kuboard
#创建kuboard
[root@kuboard ~]# docker run -d \
--restart=unless-stopped \
--name=kuboard \
-p 80:80/tcp \
-p 10081:10081/tcp \
-e KUBOARD_ENDPOINT="http://192.168.0.206:80" \
-e KUBOARD_AGENT_SERVER_TCP_PORT="10081" \
-v /root/kuboard-data:/data \
eipwork/kuboard:v3访问kuboard页面:http://server_ip
用户名:admin
密码:Kuboard123 #大写的K


评论区