




1、环境准备
省略
2、Prometheus告警规则参数全解析
上面的内容就是将alertmanager组件安装好了,小伙伴都知道Alertmanager 是专门负责告警管理的核心组件。它接收来自 Prometheus 的告警信息,并进行去重、分组、路由,最终将告警通知发送到不同的接收端。
Alertmanager主要负责对Prometheus产生的告警进行统一处理,因此在Alertmanager配置中一般会包含以下几个主要部分:
全局配置(global):用于定义一些全局的公共参数,如全局的SMTP配置,Slack配置等内容;
模板(templates):用于定义告警通知时的模板,如HTML模板,邮件模板等;
告警路由(route):根据标签匹配,确定当前告警应该如何处理;
接收人(receivers):接收人是一个抽象的概念,它可以是一个邮箱也可以是微信,Slack或者Webhook等,接收人一般配合告警路由使用;
抑制规则(inhibit_rules):合理设置抑制规则可以减少垃圾告警的产生
前提:
已提前部署Prometheus、Grafana、Node Exporter等各类需要的exporters组件,包括但不限于MySQL、Redis等等
修改好了Prometheus的配置文件prometheus.yml:用于配置告警通知管理和指定自定义的规则文件
具体步骤:
配置好Prometheus的配置文件,主要是配置自定义的规则以及
配置alertmanager配置文件(Alertmanager 负责处理 Prometheus 发送的告警,进行去重、分组、路由和通知。)
[root@prometheus ~]# vi /opt/prometheus/alertmanager/alertmanager.yml
global:
resolve_timeout: 10s # 每10秒检查一次是否恢复
smtp_smarthost: 'smtp.qq.com:465' # smtp服务器地址(用于邮件通知)需要加端口
smtp_from: 'xxxxxxxxx@qq.com' # 发件人邮箱
smtp_auth_username: 'xxxxxxxxx@qq.com' # SMTP认证用户名
smtp_auth_password: '**********' # 账号对应的授权码(不是密码),QQ邮箱授权码可以在“设置-账户-POP3/SMTP服务”里面找到点击开启
smtp_require_tls: false # 设为 false,因为使用 SSL
route:
group_by: ['alertname'] # 按哪些标签分组(['alertname', 'severity'])
group_wait: 10s # 组告警等待时间。也就是告警产生后等待10s,如果有同组告警一起发出
group_interval: 10s # 两组告警的间隔时间
repeat_interval: 2h # 重复告警的间隔时间,减少相同告警的发送频率
receiver: 'mail' # 默认接受者
routes:
- match: # 精确匹配标签(如:severity:critical)
severity: 'critical'
receiver: 'team-critical'
- match_re: #正则匹配(如team:devops|sre)
team: 'devops|sre'
receiver: 'team-devops'
receivers:
- name: 'mail' # 接收者配置
email_configs:
- to: 'xxxxxxxxx@qq.com' # 邮件接收地址
send_resolved: true # 启用已解决通知在全局配置中需要注意的是resolve_timeout,该参数定义了当Alertmanager持续多长时间未接收到告警后标记告警状态为resolved(已解决)。该参数的定义可能会影响到告警恢复通知的接收时间,读者可根据自己的实际场景进行定义,其默认值为5分钟。在接下来的部分,我们将已一些实际的例子解释Alertmanager的其它配置内容。
3、Prometheus告警规则
Prometheus中的告警规则允许你基于PromQL表达式定义告警触发条件,Prometheus后端对这些触发规则进行周期性计算,当满足触发条件后则会触发告警通知。默认情况下,用户可以通过Prometheus的Web界面查看这些告警规则以及告警的触发状态。当Promthues与Alertmanager关联之后,可以将告警发送到外部服务如Alertmanager中并通过Alertmanager可以对这些告警进行进一步的处理。
告警规则是配置在prometheus服务器
配置文件promethus.ym:用于配置告警通知管理和指定自定义的规则文件**
[root@prometheus ~]# vi /opt/prometheus/prometheus.yml ### prometheus.yml:这个配置文件包含了Prometheus的各种配置选项,如监控目标、规则等。
# Alertmanager configuration
alerting: ###alerting:告警配置部分,配置如何处理告警信息。
alertmanagers: ###alertmanagers:告警管理器的配置,这里使用静态配置方式配置Alertmanager的目标地址。
- static_configs:
- targets:
- localhost:9093 ###用于告警通知管理的alertmanager和prometheus安装在同一台机器上,所以可以配置成localhost进行访问alertmanager
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files: ###rule_files:规则文件配置部分,用于加载和周期性地评估规则。
- "rules/*.yml" ###指定自定义的规则文件
scrape_configs:
- job_name: 'alertmanager'
# 覆盖全局默认值,每15秒从该作业中刮取一次目标
scrape_interval: 15s
static_configs:
- targets: ['alertmanager:9093']4、配置告警规则
4.1、安装node_exporter
省略
4.2、Prometheus添加配置
- job_name: 'node-exporter'
scrape_interval: 15s
static_configs:
- targets: ['node_exporter:9100']
labels:
instance: Prometheus服务器4.3、创建告警规则文件
#进入到prometheus docker安装目录
cd /data/prometheus
vim prometheus/alert.yml告警规则配置如下:
groups:
- name: Prometheus alert
rules:
# 对任何实例超过1分钟无法联系的情况发出警报
- alert: 服务告警
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "服务异常,实例:{{ $labels.instance }}"
description: "{{ $labels.job }} 服务已关闭"在告警规则文件中,我们可以将一组相关的规则设置定义在一个group下。在每一个group中我们可以定义多个告警规则(rule)。一条告警规则主要由以下几部分组成:
alert:告警规则的名称。
expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
那么告警的规则会读取/opt/prometheus目录下的rules.yml 文件,yml 文件可以有多个。
groups: # 告警规则组,可以包含多个规则
- name: <string> # 规则组名称
[ interval: <duration> ] # 评估间隔
[ limit: <int> ] # 告警数量限制
rules: # 组类的告警规则列表
- alert: <string> # 告警名称
expr: <string> # PromQL表达式,用于触发告警(如 CPU 使用率 > 80%)
[ for: <duration> ] # 持续时间(如10m,表示条件持续满足后才触发告警)————避免抖动
[ labels: <map> ] # 附加到告警的标签(例如severity:warning),用于Alertmanager路由和分组
[ annotations: <map> ] # 告警的详细模板(提供人类可读的告警信息,支持模板)下面我举个例子:
# alert.rules.yml
groups: # 告警规则组,可以包含多个规则
- name: server-alerts # 规则组的名称
rules: # 组内的告警规则列表
- alert: HostHighCPU # 告警名称
expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) * 100) > 80 # PromQL表达式,用于触发告警(如 )
for: 5m # 持续 5 分钟满足条件才触发
labels: # 附加到告警的标签(如severity:warning),用于Alertmanager路由和分组
severity: warning
annotations: # 告警的详细描述(支持模板,如{{labels.instance}})
summary: "高 CPU 使用率 ({{ $labels.instance }})"
description: "实例 {{ $labels.instance }} 的 CPU 使用率已达 {{ $value }}%,持续 5 分钟。"5、指定加载告警规则
为了能够让Prometheus能够启用定义的告警规则,我们需要在Prometheus全局配置文件中通过rule_files指定一组告警规则文件的访问路径,Prometheus启动后会自动扫描这些路径下规则文件中定义的内容,并且根据这些规则计算是否向外部发送通知:
格式:
rule_files:
[ - <filepath_glob> ... ]具体配置
# 报警(触发器)配置
rule_files:
- "alert.yml"
- "rules/*.yml"重启配置文件
curl -X POST http://localhost:9090/-/reload6、查看告警状态
重启Prometheus后,用户可以通过Prometheus WEB界面中的Alerts菜单查看当前Prometheus下的所有告警规则,以及其当前所处的活动状态。
同时对于已经pending或者firing的告警,Prometheus也会将它们存储到时间序列ALERTS{}中。
可以通过表达式,查询告警实例:
ALERTS{}样本值为1表示当前告警处于活动状态(pending或者firing),当告警从活动状态转换为非活动状态时,样本值则为0。
7、测试告警规则
在主机上运行以下命令:
docker stop node-exporterPrometheus首次检测到满足触发条件后,由于告警规则中设置了1分钟(for: 1m)的等待时间,告警状态从INACTIVE变为Pending,如下图所示:
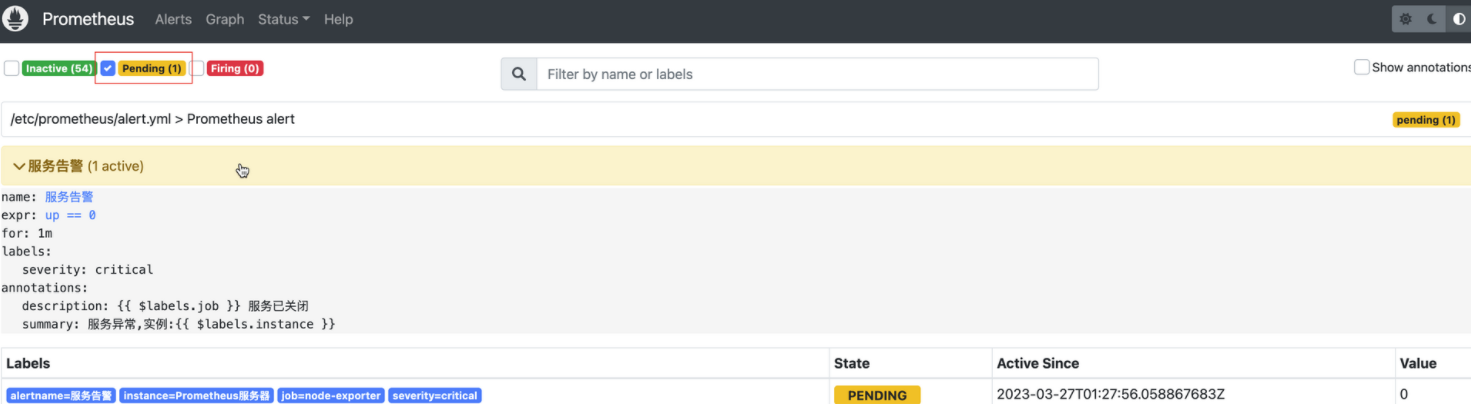
如果1分钟后告警条件持续满足,告警状态从Penging变为FIRING,并且会把告警信息发送给alertmanager。如下图所示:
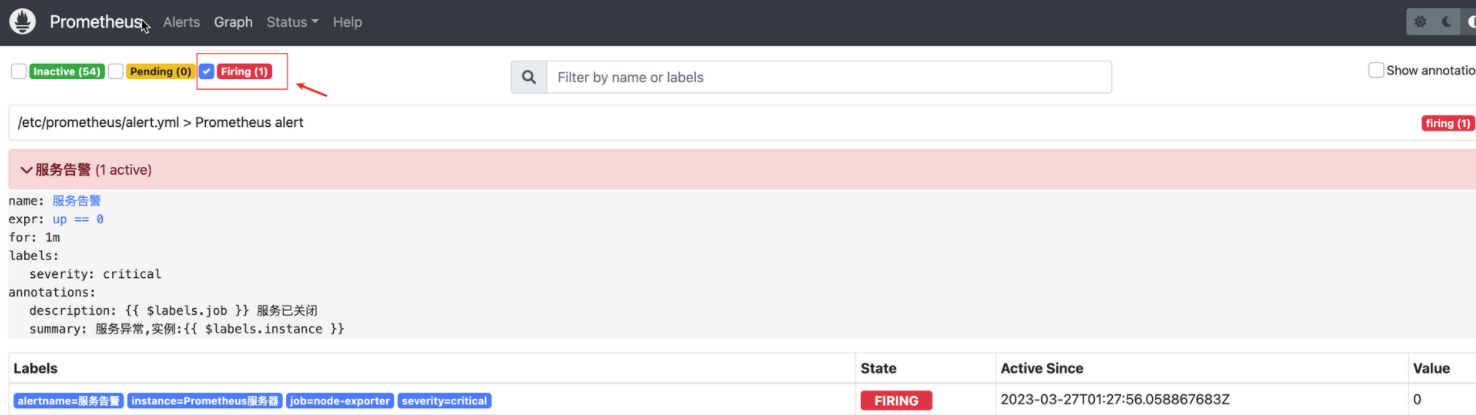
注:如果for: 0或者没有配置for,检测到满足触发条件,那告警状态从
INACTIVE变为FIRING,把告警信息发送给alertmanager
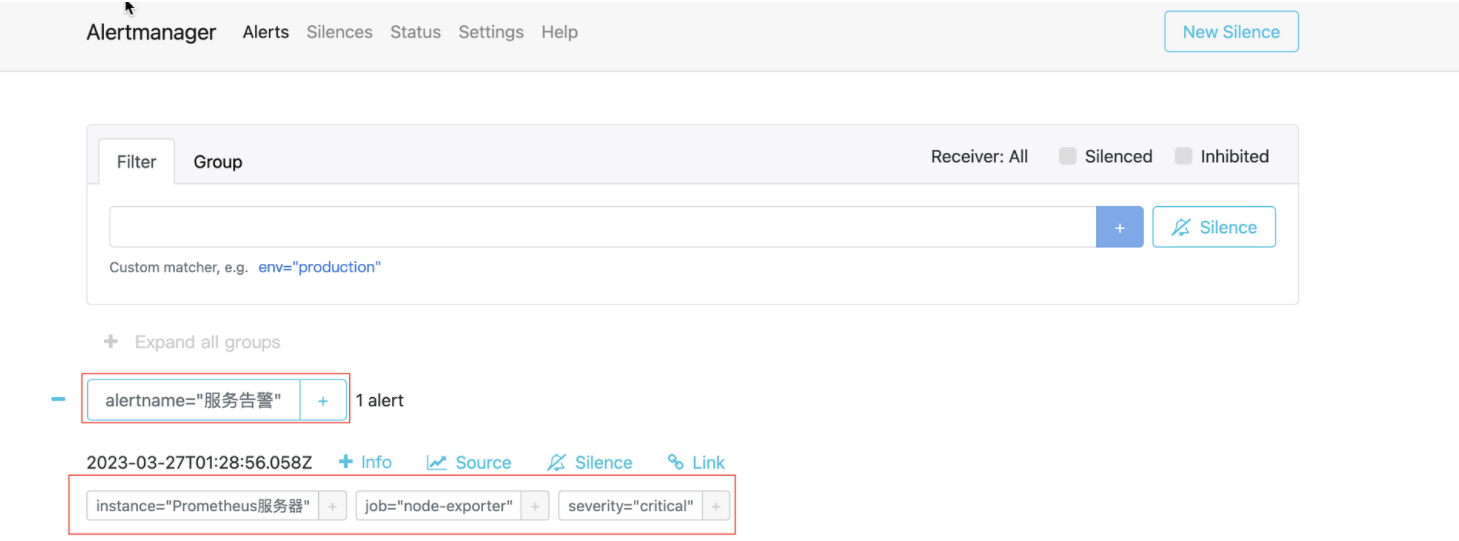
alertmanager接收到告警信息如下图:
8、PromQL查询
up == 0结果
up{instance="Prometheus服务器", job="node-exporter"} 0

评论区