




1、二元运算符
Prometheus 的查询语言支持基本的逻辑运算和算术运算。对于两个瞬时向量, 匹配行为可以被改变。
1.1 算术二元运算符
在Prometheus系统中支持下面的二元算术运算符:
+加法-减法*乘法/除法%模^幂等
二元运算操作符支持 scalar/scalar(标量/标量)、vector/scalar(瞬时向量/标量)、和 vector/vector(瞬时向量/瞬时向量) 之间的操作。
在两个标量之间进行数学运算,得到的结果也是标量。
表达式:
(63+3)*3结果
scalar 198瞬时向量和标量之间进行算数运算时,算术运算符会一次作用与瞬时向量中的每一个样本值,从而得到一组新的时间序列
例如:我们通过监控指标node_memory_MemTotal_bytes(主机内存总大小)单位为byte,如果换成mb时。
表达式:
node_memory_MemTotal_bytes/(1024*1024)结果
{instance="Prometheus服务器", job="node-exporter"} 3901.07421875
{instance="test服务器", job="node-exporter"} 3901.04296875瞬时向量与瞬时向量之间进行数学运算时,过程会相对复杂一点,
运算符会依次找到与左边向量元素匹配(标签完全一致)的右边向量元素进行运算,如果没找到匹配元素,则直接丢弃。同时新的时间序列将不会包含指标名称。
例如,如果我们 node_memory_MemAvailable_bytes(可用内存) 和 node_memory_MemTotal_bytes(总内存) 获取内存可用率%,可以使用如下表达式:
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100结果:
{instance="Prometheus服务器", job="node-exporter"} 73.19077778055924
{instance="test服务器", job="node-exporter"} 69.0442359665434案例:幂运算
process_open_fds ^ 31.2 关系运算符
目前,Prometheus 支持以下关系运算符:
==(相等)!=(不相等)>(大于)<(小于)>=(大于等于)<=(小于等于)
关系运算符被应用于 scalar/scalar(标量/标量)、vector/scalar(瞬时向量/标量),和vector/vector(瞬时向量/向量)。默认情况下关系运算符只会根据时间序列中样本的值,对时间序列进行过滤。我们可以通过在运算符后面使用 bool 修饰符来改变关系运算的默认行为。使用 bool 修改符后,关系运算不会对时间序列进行过滤,而是直接依次瞬时向量中的各个样本数据与标量的比较结果 0 或者 1。
在两个标量之间进行关系运算,必须提供 bool 修饰符,得到的结果也是标量,即 0(false)或 1(true)。
例如:
2 > bool 1 # 结果为 1瞬时向量和标量之间的关系运算,这个运算符会应用到某个当前时刻的每个时序数据上,如果一个时序数据的样本值与这个标量比较的结果是 false,则这个时序数据被丢弃掉,如果是 true, 则这个时序数据被保留在结果中。如果提供了 bool 修饰符,那么比较结果是 0 的时序数据被丢弃掉,而比较结果是 1 的时序数据被保留。
例如:
node_load1 > 1 # 结果为 true 或 false
node_load1 > bool 1 # 结果为 1 或 0
up == 1
up !=1瞬时向量与瞬时向量直接进行关系运算时,同样遵循默认的匹配模式:依次找到与左边向量元素匹配(标签完全一致)的右边向量元素进行相应的操作,如果没找到匹配元素,或者计算结果为 false,则直接丢弃。如果匹配上了,则将左边向量的度量指标和标签的样本数据写入瞬时向量。如果提供了 bool 修饰符,那么比较结果是 0 的时序数据被丢弃掉,而比较结果是 1 的时序数据(只保留左边向量)被保留。
例如:
node_memory_MemAvailable_bytes > bool node_memory_MemTotal_bytes
或
node_memory_MemAvailable_bytes < bool node_memory_MemTotal_bytes1.3 集合运算符
使用瞬时向量表达式能够获取到一个包含多个时间序列的集合,我们称为瞬时向量。 通过集合运算,可以在两个瞬时向量与瞬时向量之间进行相应的集合操作。目前,Prometheus 支持以下集合运算符:
and(并且)or(或者)unless(排除)
vector1 and vector2 会产生一个由vector1的元素组成的新的向量。该向量包含vector1中完全匹配vector2中的元素。
vector1 or vector2 会产生一个新的向量,该向量包含vector1的所有原始元素(标签集+值)的向量,以及vector2中没有与vector1匹配标签集的所有元素。
vector1 unless vector2 会产生一个由vector1的元素组成的向量,而这些元素在vector2中没有与标签集完全匹配的元素,两个向量中的所有匹配元素都被删除。
and表达式:
node_cpu_seconds_total{mode=~"idle|user|system"} and node_cpu_seconds_total{mode=~"user|system|iowait"}#时钟不同步触发器
min_over_time(node_timex_sync_status[1m]) == 0 and node_timex_maxerror_seconds >= 16or表达式
node_cpu_seconds_total{mode=~"idle|user|system"} or node_cpu_seconds_total{mode=~"user|system|iowait"}#状态码非200-399触发器
probe_http_status_code <= 199 OR probe_http_status_code >= 400unless表达式
node_cpu_seconds_total{mode=~"idle|user|system"} unless node_cpu_seconds_total{mode=~"user|system|iowait"}2、聚合操作
Prometheus 还提供了下列内置的聚合操作符,这些操作符作用域瞬时向量。可以将瞬时表达式返回的样本数据进行聚合,形成一个具有较少样本值的新的时间序列。
sum(求和)min(最小值)max(最大值)avg(平均值)stddev(标准差)stdvar(标准差异)count(计数)count_values(对 value 进行计数)bottomk(样本值最小的 k 个元素)topk(样本值最大的k个元素)quantile(分布统计)
这些操作符被用于聚合所有标签维度,或者通过 without 或者 by 子语句来保留不同的维度。
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]其中只有 count_values, quantile, topk, bottomk 支持参数(parameter)。
without(排除标签名称)
by(保留标签名称): 类似sql的:goup by
2.1 sum结果求和
表达式:
sum(node_cpu_seconds_total) without (cpu,job,mode)等价于
sum(node_cpu_seconds_total) by (instance)计算prometheus http请求总量,表达式:
sum(prometheus_http_requests_total)2.2 max最大值
max(node_cpu_seconds_total) by (mode)2.3 avg平均值
avg(node_cpu_seconds_total) by (mode)cpu负载> 80%触发器
100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 802.4 count (统计数量)
count(prometheus_http_requests_total)2.5 bottomk(统计最小的几个值)
bottomk(3, sum(node_cpu_seconds_total) by (mode))2.6 topk(统计最大的几个值)
类似sql:ORDER BY vaule DESC limit 3
topk(3, sum(node_cpu_seconds_total) by (mode))3 基于时间聚合
前面我们已经学习了如何使用 sum()、avg() 和相关的聚合运算符从标签维度进行聚合,这些运算符在一个时间内对多个序列进行聚合,但是有时候我们可能想在每个序列中按时间进行聚合,例如,使尖锐的曲线更平滑,或深入了解一个序列在一段时间内的最大值。
为了基于时间来计算这些聚合,PromQL 提供了一些与标签聚合运算符类似的函数,但是在这些函数名前面附加了 _over_time():
avg_over_time(range-vector):区间向量内每个指标的平均值。min_over_time(range-vector):区间向量内每个指标的最小值。max_over_time(range-vector):区间向量内每个指标的最大值。sum_over_time(range-vector):区间向量内每个指标的求和。count_over_time(range-vector):区间向量内每个指标的样本数据个数。quantile_over_time(scalar, range-vector):区间向量内每个指标的样本数据值分位数。stddev_over_time(range-vector):区间向量内每个指标的总体标准差。stdvar_over_time(range-vector):区间向量内每个指标的总体标准方差。
3.1 max_over_time
#MySQL运行的线程过多触发器,1分钟最大的值
max_over_time(mysql_global_status_threads_running[1m]) > 203.2 avg_over_time
#HTTP请求慢告警触发器,1分钟平均的值
avg_over_time(probe_duration_seconds[1m]) > 13.3 min_over_time
#时钟不同步告警触发器,1分钟最小的值
min_over_time(node_timex_sync_status[1m]) == 04 向量匹配
在标量和瞬时向量之间使用运算符可以满足很多需求,但是在两个瞬时向量之间使用运算符时,哪些样本应该适用于哪些其他样本?这种瞬时向量的匹配称为向量匹配。Prometheus提供了两种基本的向量匹配模式:one-to-one向量匹配和many-to-one(one-to-many)向量匹配。
接下来将介绍在 PromQL 中有两种典型的匹配模式:一对一(one-to-one),多对一(many-to-one)或一对多(one-to-many)。
4.1 一对一(one-to-one)
一对一匹配模式会从操作符两边表达式获取的瞬时向量依次比较并找到唯一匹配(标签完全一致)的样本值。默认情况下,
使用表达式:
vector1 <operator> vector2例如当存在样本:
process_open_fds{instance="Prometheus服务器", job="node-exporter"} 9
process_max_fds{instance="Prometheus服务器", job="node-exporter"} 1048576使用 PromQL 案例:
process_open_fds{instance="Prometheus服务器", job="node-exporter"} / process_max_fds{instance="Prometheus服务器", job="node-exporter"}因此结果如下:
{instance="Prometheus服务器", job="node-exporter"} 0.00000858306884765625在操作符两边表达式标签不一致的情况下,可以使用 on(label list) 或者 ignoring(label list)来修改便签的匹配行为。使用 ignoreing 可以在匹配时忽略某些便签。而 on 则用于将匹配行为限定在某些便签之内。
<vector expr> <bin-op> ignoring(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) <vector expr>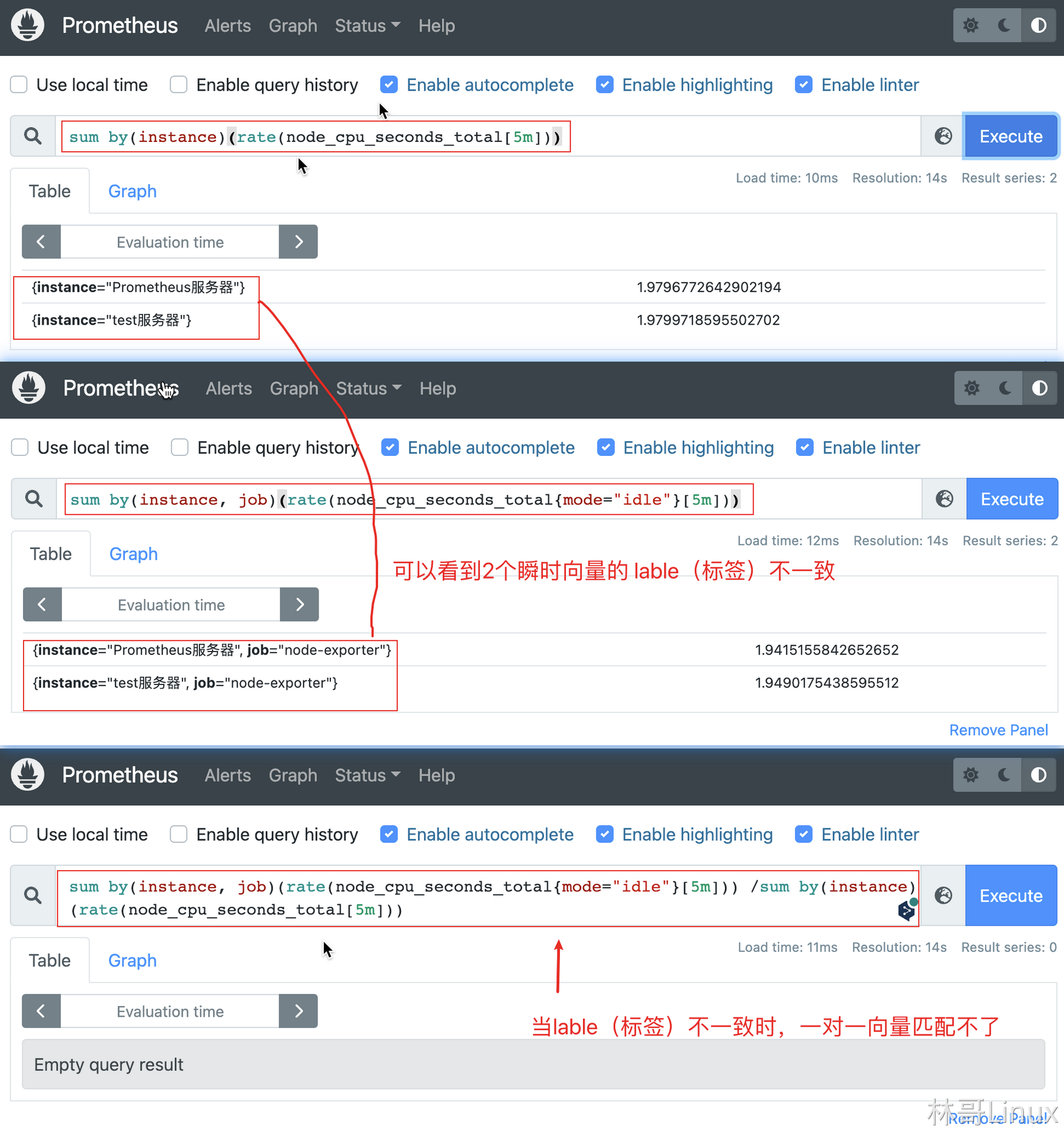
表达式
sum by(instance, job)(rate(node_cpu_seconds_total{mode="idle"}[5m]))表达式
sum by(instance)(rate(node_cpu_seconds_total[5m]))使用on表达式:
sum by(instance, job)(rate(node_cpu_seconds_total{mode="idle"}[5m])) / on(instance) sum by(instance)(rate(node_cpu_seconds_total[5m]))结果
{instance="Prometheus服务器"} 0.9803643329726668
{instance="test服务器"} 0.98493442041828874.2 多对一和一对多
多对一和一对多的匹配模式,可以理解为向量元素中的一个样本数据匹配到了多个样本数据标签。在使用该匹配模式时,需要使用group_left或group_right修饰符明确指定哪一个向量具有更高的基数,也就是说左或者右决定了哪边的向量具有较高的子集。此表达格式为:
<vector expr> <bin-op> ignoring(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> ignoring(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_right(<label list>) <vector expr>多对一和一对多两种模式一定是出现在操作符两侧表达式返回的向量标签不一致的情况。因此需要使用 ignoring 和 on 修饰符来排除或者限定匹配的标签列表。
使用group_left指定左侧操作数组中可以有多个匹配样本
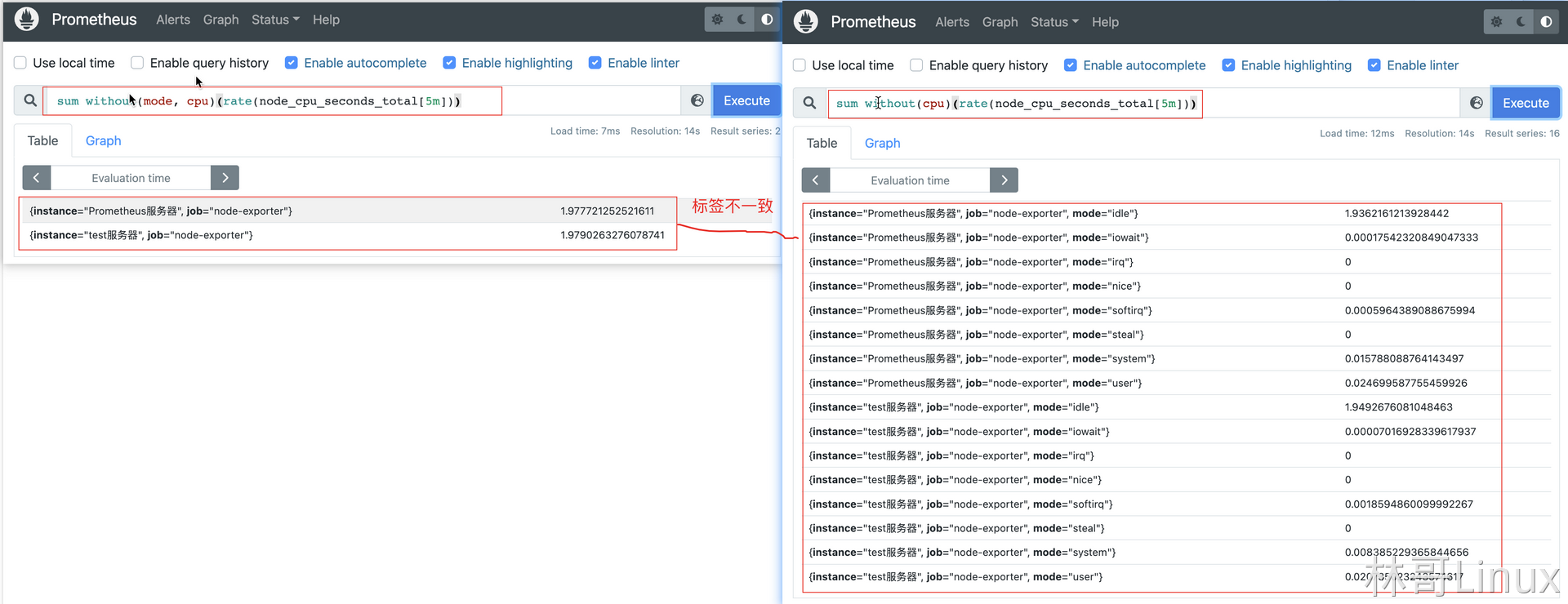
例如,表达式:
sum without(cpu)(rate(node_cpu_seconds_total[5m])) / ignoring(mode) group_left sum without(mode, cpu)(rate(node_cpu_seconds_total[5m]))结果:
{instance="Prometheus服务器", job="node-exporter", mode="idle"} 0.9802134676075311
{instance="Prometheus服务器", job="node-exporter", mode="iowait"} 0.000035459735470373514
{instance="Prometheus服务器", job="node-exporter", mode="irq"} 0
{instance="Prometheus服务器", job="node-exporter", mode="nice"} 0.000017729867735189905
{instance="Prometheus服务器", job="node-exporter", mode="softirq"} 0.0003368674869685515
{instance="Prometheus服务器", job="node-exporter", mode="steal"} 0
{instance="Prometheus服务器", job="node-exporter", mode="system"} 0.008049359951775699
{instance="Prometheus服务器", job="node-exporter", mode="user"} 0.01134711535051912
{instance="test服务器", job="node-exporter", mode="idle"} 0.9848852662354926
{instance="test服务器", job="node-exporter", mode="iowait"} 0.00001771950031008937
{instance="test服务器", job="node-exporter", mode="irq"} 0
{instance="test服务器", job="node-exporter", mode="nice"} 0
{instance="test服务器", job="node-exporter", mode="softirq"} 0.0007796580136441839
{instance="test服务器", job="node-exporter", mode="steal"} 0
{instance="test服务器", job="node-exporter", mode="system"} 0.00425268007442165
{instance="test服务器", job="node-exporter", mode="user"} 0.010064676176131668左右两边的瞬时向量标签不一致:
5 二元运算符优先级
在 Prometheus 系统中,二元运算符优先级从高到低的顺序为:
^*,/,%+,-==,!=,<=,<,>=,>and,unlessor
具有相同优先级的运算符是满足结合律的(左结合)。例如,2 * 3 % 2 等价于 (2 * 3) % 2。运算符 ^ 例外,^ 满足的是右结合,例如,2 ^ 3 ^ 2 等价于 2 ^ (3 ^ 2)。


评论区